处理CBO的SQL优化问题(图文详细说明)
时间:2025/3/12作者:未知来源:盾怪网教程人气:
- [摘要]alias,n) ,这个hint很有用, 它可以让CBO优化器认为表的行数是n,这样就可以改变执行计划了。现在改写上面的查询:加了cardinality(tab,5)自动走CBO优化器了,优化器把表...alias,n) ,这个hint很有用, 它可以让CBO优化器认为表的行数是n,这样就可以改变执行计划了。现在改写上面的查询:
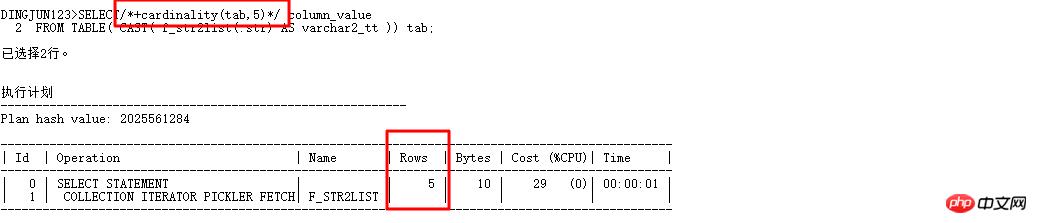
加了cardinality(tab,5)自动走CBO优化器了,优化器把表的基数看成5,前面的where in list查询基数默认为8168的时候走的是hash join,现在有了cardinality,赶紧试试:
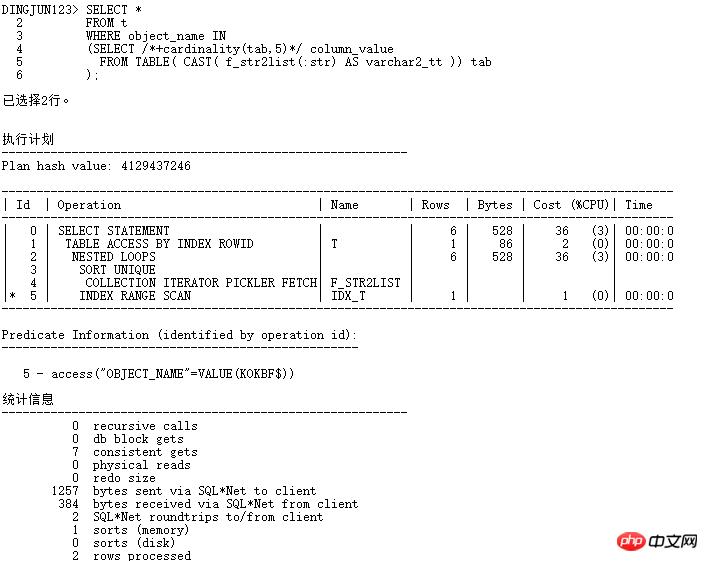
现在走NESTED LOOPS操作,子节点可以走INDEX RANGE SCAN,逻辑读从184变成7,效率提升数十倍。当然,实际应用中,最好不要加hints,可以使用SQL PROFILER绑定。
3 选择性计算不准确问题
Oracle内部计算选择性都是以数字格式计算,因此,遇到字符串类型,会将字符串转换成RAW类型,再将RAW类型转换成数字,并且ROUND到左起15位,这样对于转换后的数字很大,可能原来字符串相差比较大的,内部转换后的数字比较接近,这样就会引起选择性计算不准确问题。如下例:

执行计划如下:
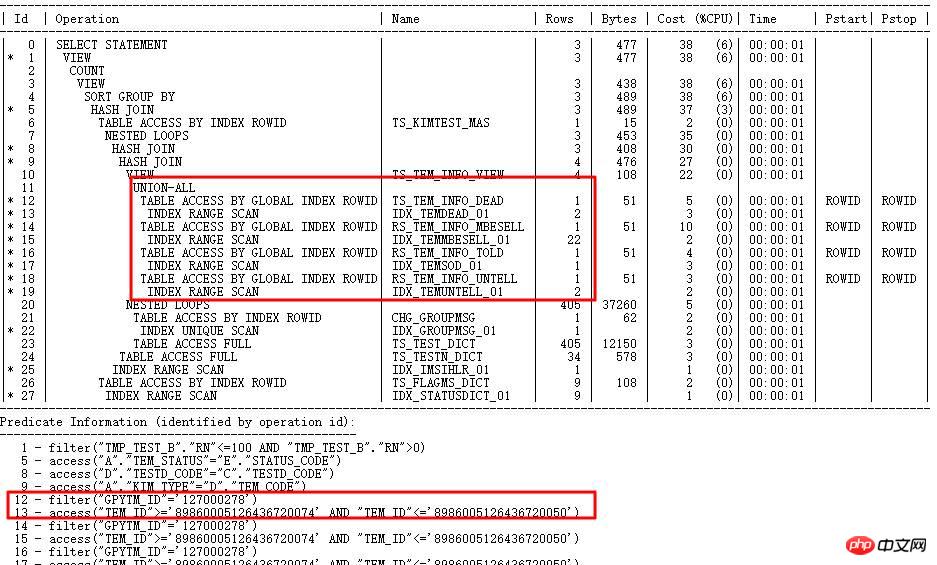
SQL执行计划走TEM_ID索引,需要运行1小时以上,计划中对应步骤cardinality很少(几十级别),实际很大(百万级别),判断统计信息出错。
为什么走错索引?
由于TEM_ID是CHAR字符串类型,长度20,CBO内部计算选择性会先将字符串转为RAW,然后RAW转为数字,左起ROUND 15位。因此,可能字符串值差别大的,转换成数字后值接近(因为超出15位补0),导致选择性计算错误。以TS_TEM_INFO_DEAD中的TEM_ID列为例:

而实际根据条件查询出的行数 29737305。因此,索引走错了。
解决方法:
收集TEM_ID列直方图,由于内部算法有一定限制,导致值不同的字符串,内部计算值可能一致,所以收集直方图后,针对字符串值不同,但是转换成数字后相同的,ORACLE会将实际值存储到ENDPOINT_ACTUAL_VALUE中,用于校验,提高执行计划的准确性。走正确索引GPYTM_ID后,运行时间从1小时以上到5s内。
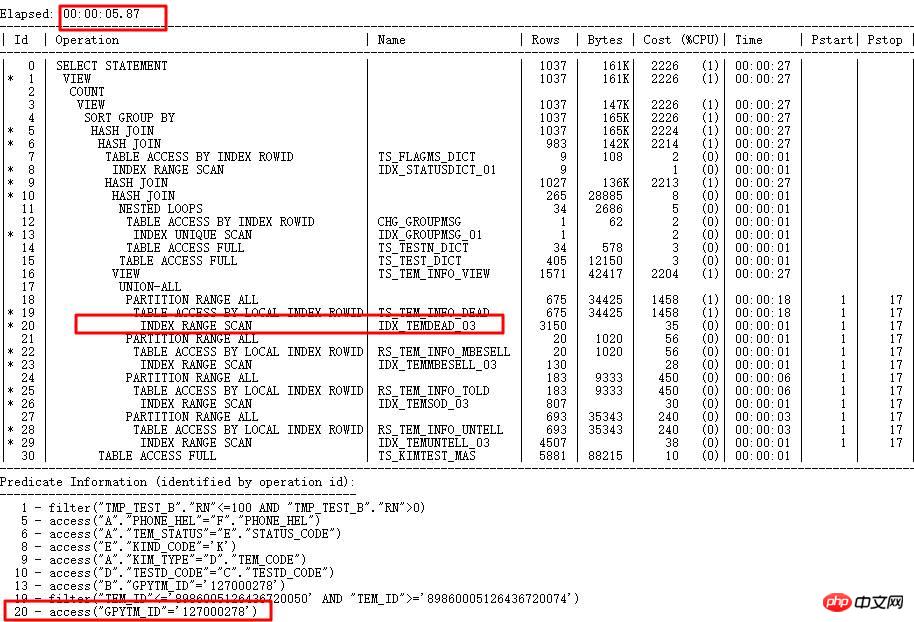
4 新特性引发执行出错问题
每个版本都会引入很多新特性,对于新特性,使用不当可能会引发一些严重问题,常见的比如ACS、cardinality feedback导致执行计划变动频繁,影响效率,子游标过多等,所以,针对新特性需要谨慎使用,包括前面说的11g null aware anti join也存在很多BUG。
今天要分析的案例是10g到11g大版本升级过程中遇到的SQL,在10g中正常运行,但是到11g中却执行出错。 SQL如下:
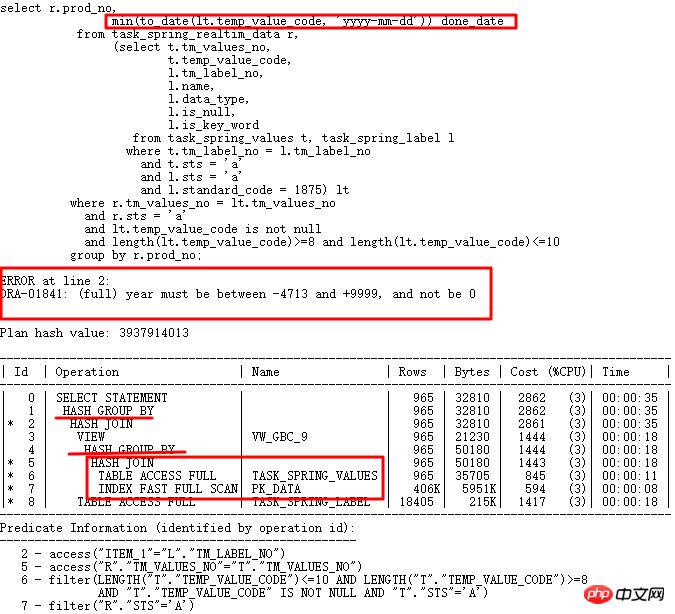
10g正常,升级11g r2后日期转换出错,temp_value_code存多种格式字符串。正确执行计划LT关联查询先执行,之后与外表关联。错误执行计划是TASK_SPRING_VALUES先与外表关联然后分组,作为VIEW再与TASK_SPRING_LABEL关联,再次进行分组,这里有2个GROUP BY操作,与10g执行计划中只有1个GROUP BY操作不同,最终导致报错。
很显然,对于为什么出现两个GROUP BY操作,需要进行研究,首选10053:
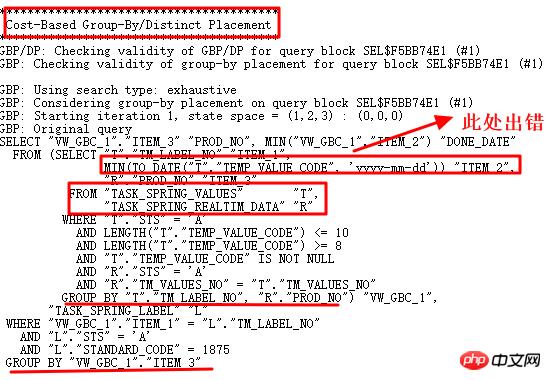
分析按照10053操作,是否找到非日期格式值:
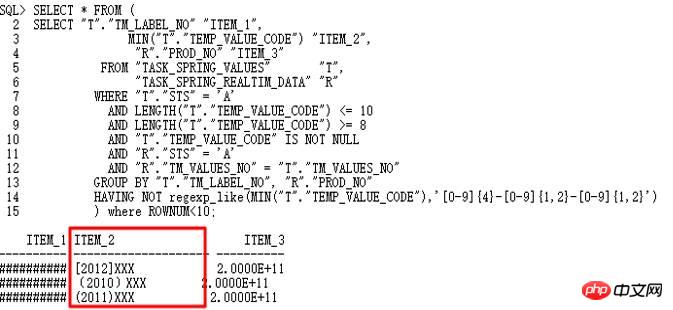
的确找到非yyyy-mm-dd格式字符串,因此,to_date操作失败。通过10053可以看出,这里使用了Group by/Distinct Placement操作,因此,需要找到对应的控制参数,关闭此查询转换。
关闭GBP隐含参数后正确:_optimizer_group_by_placement。正确执行计划如下:
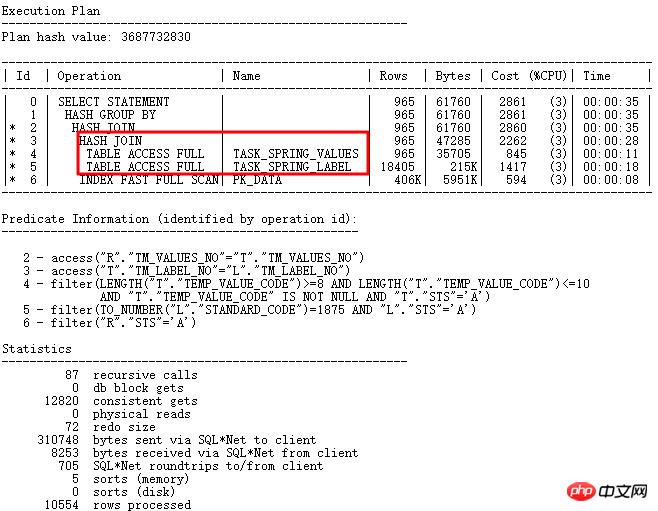
思考: 这个问题的本质在于字段用途设计不合理,其中temp_value_code作为varchar2存储普通字符、数字型字符、日期格式yyyy-mm-dd,程序中有to_number,to_date等转换,非常依赖于执行计划中表连接和条件的先后顺序。所以,良好的设计很重要,特别要保证各关联字段类型的一致性以及字段作用的单一性,符合范式要求。
5 坑爹写法CBO无能为力
结构优良的SQL能够更易被CBO理解,从而更好地进行查询转换操作,从而为后续生成最佳执行计划打下基础,然后实际应用过程中,因为不注重SQL写法,导致CBO也无能为力。下面以分页写法案例作为探讨。
低效分页写法:

原写法最内层根据use_date等条件查询,然后排序,获取rownum并取别名,最外层使用rn规律。问题在哪?
分页写法如果直接<,<=可在排序后直接rownum获取(两层嵌套),如果需要获取区间值,在最外层获取>,>=(三层嵌套)。
此语句获取<=,而使用三层嵌套,导致无法使用分页查询STOPKEY算法,因为rownum会阻止谓词推入,导致执行计划中没有STOPKEY操作。
<=分页只需要2层嵌套,done_date列有索引,根据条件done_date>to_date(‘20150916’,‘YYYYMMDD’)和只获取前20行,可高效利用索引和STOPKEY算法,改写完成后使用索引降序扫描,执行时间从1.72s到0.01s,逻辑IO 从42648到59,具体如下:

高效分页写法应该符合规范,并且能够充分利用索引消除排序。
6 CBO BUG问题
CBO BUG出现比较多的就是在查询转换中,一旦出现BUG,可能查找就比较困难,这时候应该通过分析10053或者通过使用SQLT XPLORE快速找到问题根源。如下例:
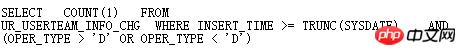
这个表的oper_type有索引,并且条件oper_type>’D’ or oper_type<’D’走索引较好,但是实际上Oracle却走了全表扫描,通过SQLT XPLORE快速分析:
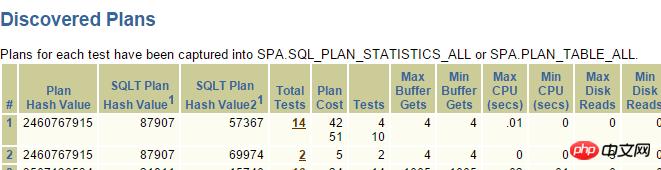
其中上面2个是走索引的执行计划,点进去:
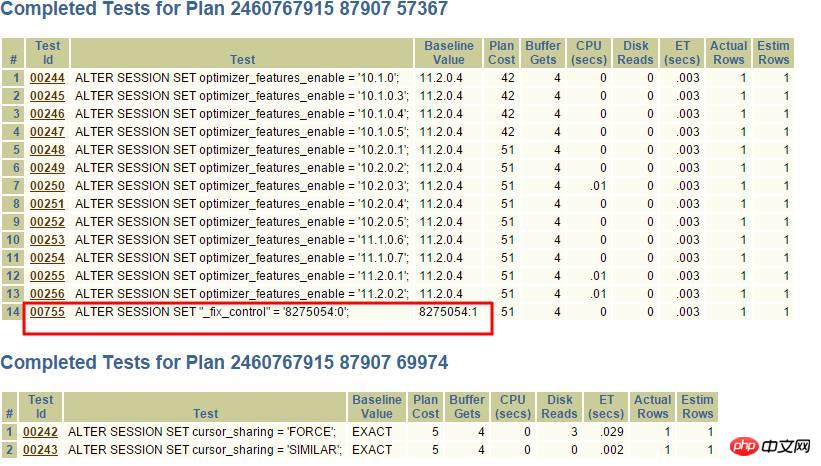
很显然,_fix_control=8275054很可疑,通过查询MOS:

转换成a<>b,很显然使用不了索引了,可以通过关闭此8275054解决。
7 HASH碰撞问题
HASHJOIN是专门用来做大数据处理的高效算法,并且只能用于等值连接条件,针对表build table(hash table)和probe table构建HASH运算,查找满足条件的结果集。
一般格式如下:
HASH JOIN
build table
probe table
这里的build table应该选择通过过滤条件过滤后,结果集尺寸较小的表(size不是rows),然后按照连接条件进行HASH函数运算,把需要的列和HASH函数运算结果存储到hash bucket中,hash bucket自身是链表结构。同样,对于probe table也需要进行hash函数运算,并根据运算结果到build table的hash bucket中去查询,查到满足,查不到丢弃。当然,ORACLE HASH JOIN内部构造还是很复杂的,具体可以参考Jonathan Lewis的CBO原理书。
HASH查找天生存在的问题:
一旦build table的连接条件列选择性不好(也就是重复值特别多),那么某些hash bucket上可能存储大量数据,由于hash bucket自身是链表结构,那么当查询这些hash bucket时,效率会急剧下降,此问题就是HASH运算的经典问题Hash Collision(HASH碰撞)。
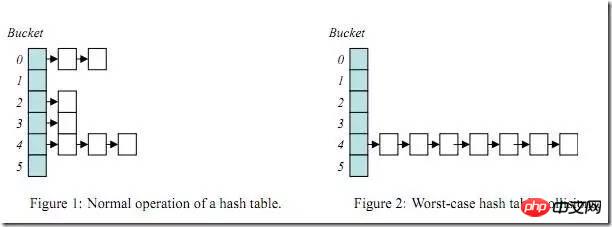
下面用一个小例子来分析下hash碰撞:
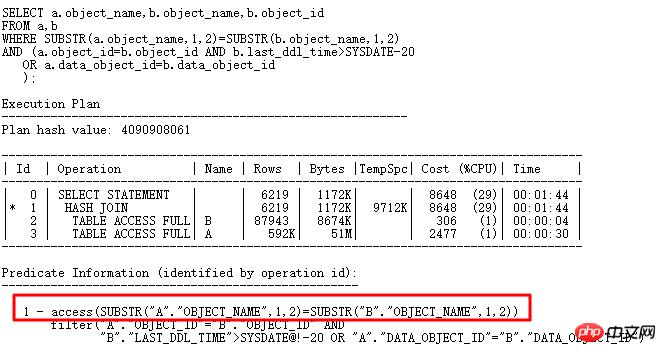
其中 a 表 61w 多条记录, b 表 7w 多条记录,此 SQL 结果返回 8w 多条记录,从执行计划来看,做 HASH JOIN 运算没有什么问题,但是实际此 SQL 执行 10 多分钟都没有执行完,效率非常低下, CPU 使用率突增,远远大于访问两个表的时间。
如果你了解HASHJOIN,这时候,你应当考虑是不是遇到hash collision了,如果很多bucket上存储大量数据,那么对于这样的hash bucket里的数据查找那就类似于nested loops了,必然效率大减。如下进一步分析:

查找一下大于重复数据大于3000条的值,果然有很多,当然剩下数据也有很多比较大,探测HASH JOIN,可以使用EVENT 10104:
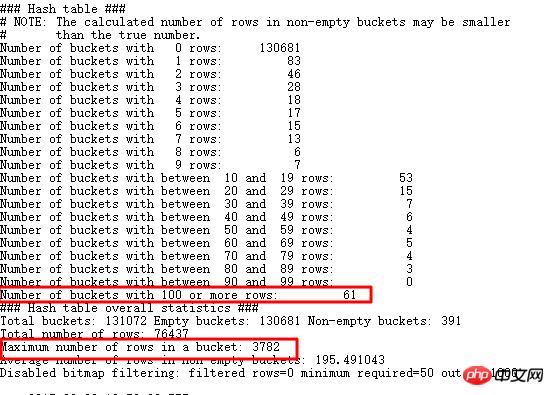
可以看到存储100行+的bucket有61个,而且最多的一个bucket中存储了3782条,也就是和我们查询出来的一致。还是回到原始SQL:
Oralce为什么选择substr(b.object_name,1,2)来构建HASH表呢,如果能将OR展开,原始SQL改为一个UNION ALL形式的,那么HASH表可以采用substr(b.object_name,1,2)和b.object_id以及data_object_id来构建,那么必然唯一性很好,那应该可以解决hash collision问题,改写如下:

现在的SQL执行时间从原来的10几分钟都没有结果,到4s执行完毕,再来看内部构建的HASHTABLE信息:
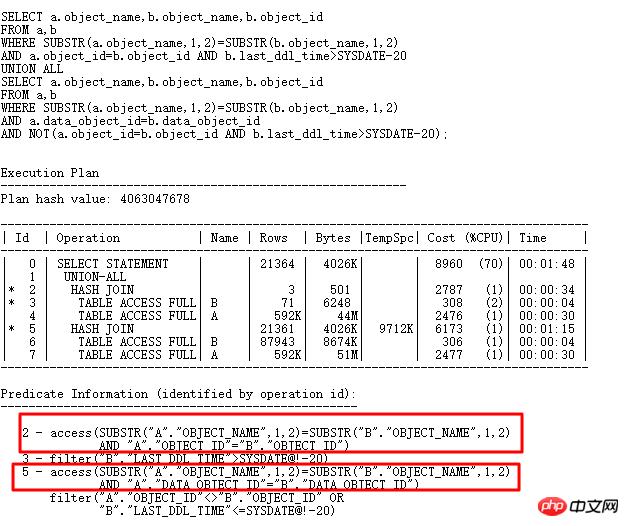
最多的一个bucket中只存储6条数据,那肯定性能比前面好很多了。Hash碰撞的危害很大,实际应用中,可能比较复杂,如果遇到hash碰撞问题,最好的方式就是进行SQL重写,尽量从业务上分析,能不能增加其它选择性比较好的列进行JOIN。
回头来看看,既然我都知道改写成UNION ALL后,就采用2个组合列构建比较好的HASH表,那么 Oracle 为什么不这样做呢?很简单,我这里只是举例刻意这么做的而已,用以说明HASH碰撞的问题,对于这种简单SQL,有选择性更好的列,收集下统计信息,Oracle就可以将的SQL进行OR展开了。
三、加强SQL审核,解决性能问题于襁褓之中
应用系统SQL众多,如果总是作为救火队员角色解决线上问题,显然不能满足当今IT系统高速发展的需求,基于数据库的系统,主要性能问题在于SQL语句,如果能在开发测试阶段就对SQL语句进行审核,找出待优化SQL,并给予智能化提示,快速辅助优化,则可以避免众多线上问题。另外,还可以对线上SQL语句进行持续监控,及时发现性能存在问题的语句,从而达到SQL的全生命周期管理目的。
为此,公司结合多年运维和优化经验,自主研发了SQL审核工具,极大提升SQL审核优化和性能监控处理效率。
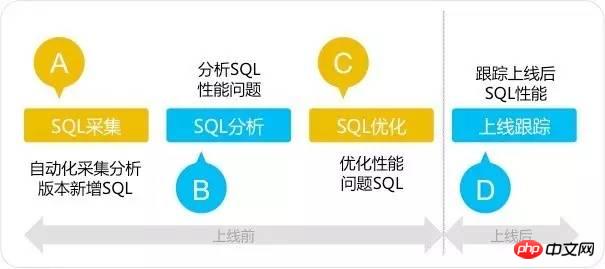
SQL审核工具采用四步法则:SQL采集―SQL分析―SQL优化―上线跟踪,SQL审核四步法区别传统的SQL优化方法,它着眼于系统上线前的SQL分析和优化,重点解决SQL问题于系统上线前,扼杀性能问题于襁褓之中。如下图所示:
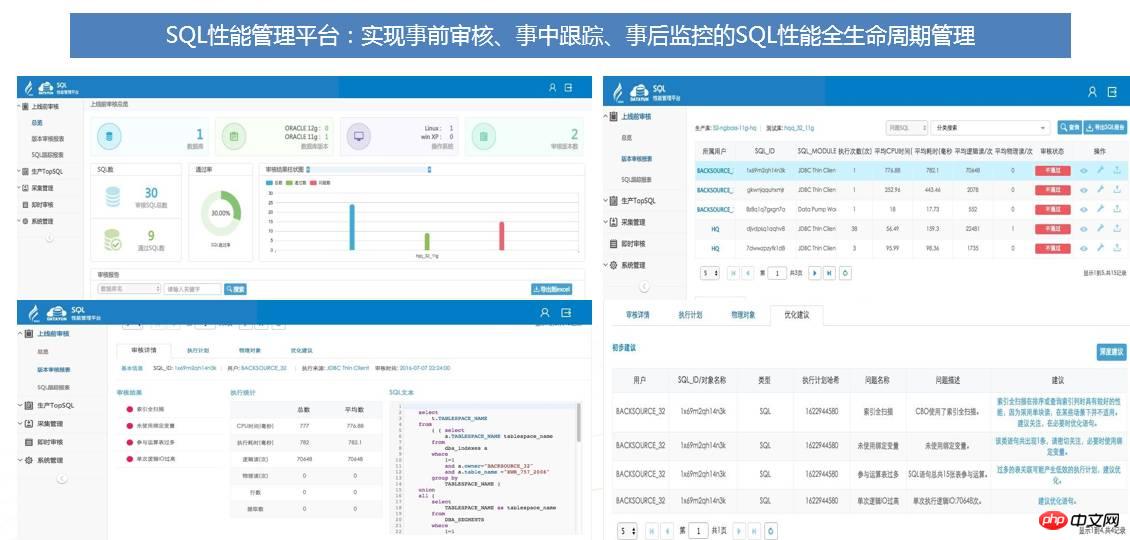
通过SQL性能管理平台可解决下列问题:
事前 : 上线前 SQL 性能审核,扼杀性能问题于襁褓之中;
事中:SQL性能监控处理,及时发现上线后SQL性能发生的变化,在SQL性能变化并且没有引起严重问题时,及时解决;
事后:TOPSQL监控,及时告警处理。
SQL性能管理平台实现了SQL性能的360度全生命周期管控,并且通过各种智能化提示和处理,将绝大多数本来因SQL引发的性能问题,解决在问题发生之前,提高系统稳定度。
下面是SQL审核的一个典型案例:
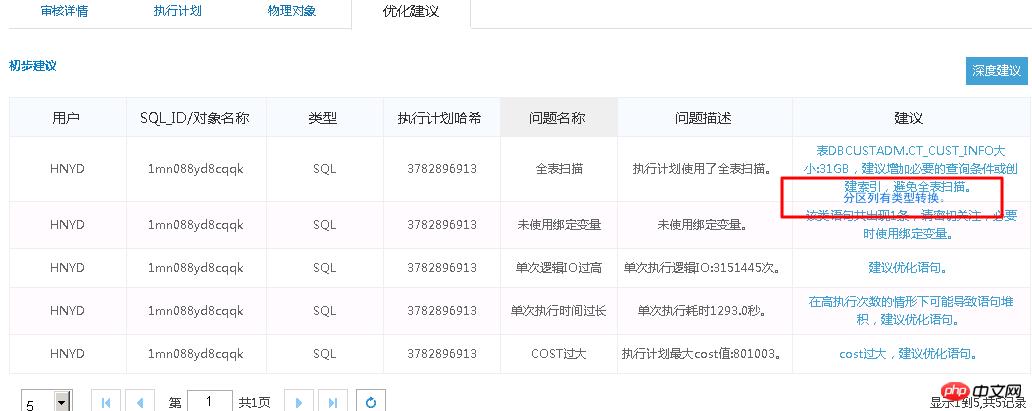
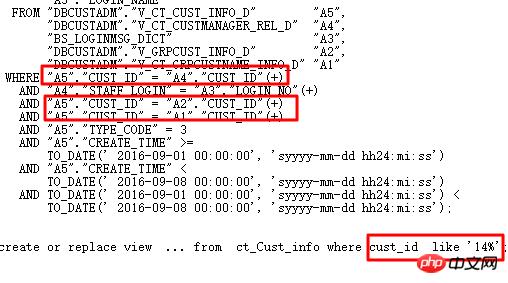
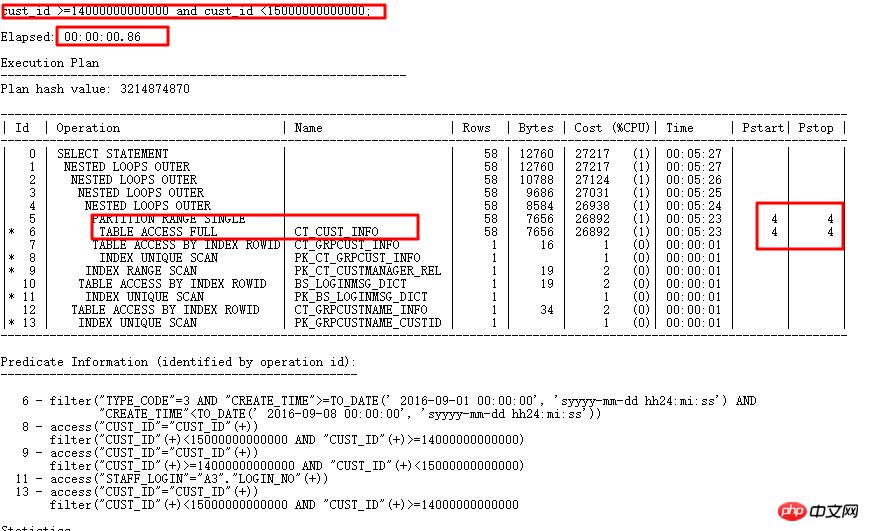
执行计划如下:
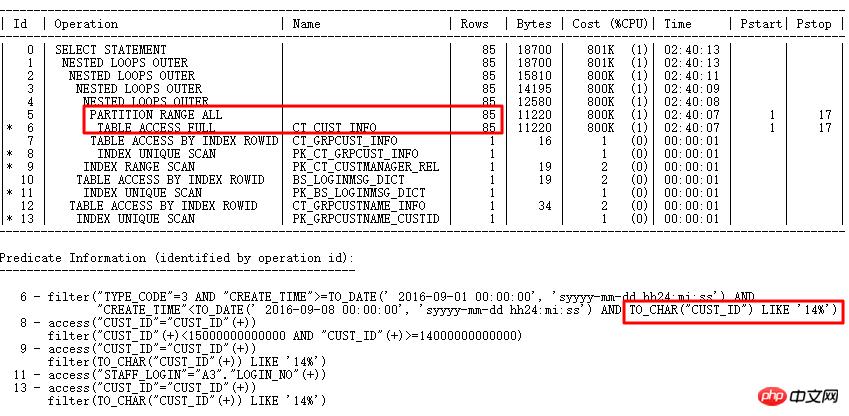
原SQL执行1688s。通过SQL审核智能优化准确找到优化点―分区列有类型转换。 优化后0.86s。
SQL审核是新炬数据库性能管理平台DPM的一个模块,想了解更多关于DPM的信息,可加邹德裕大师(微信:carydy)交流探讨。
今天主要和大家分享了一些Oracle优化器中存在的问题以及常见问题解决方法,当然,优化器问题不仅限于今天分享的,虽然CBO非常强大,并且在12c中有巨大改进,但是,存在的问题也很多,只有平时多积累和观察,掌握一定的方法,在能在遇到问题事后运筹帷幄,决胜千里。
Q&A
Q1: hash join是不是有排序,可以简单说说hash join的原理吗?
A1: ORACLE HASH JOIN自身不需要排序,这是区别SORTMERGE JOIN特点之一。ORACLE HASH JOIN原理比较复杂,可以参考Jonathan Lewis的Cost-Based Oracle Fundamentals的HASH JOIN部分,针对HASHJOIN最重要的是在原理基础上搞清楚什么时候会慢,比如HASH_AREA_SIZE过小,HASH TABLE不能完全放到内存中,那么会发生磁盘HASH运算,再比如上面讲的HASH碰撞发生。
Q2: 什么时候不走索引?
A2: 不走索引情况比较多,首要的原因就是统计信息不准导致的,第二原因就是选择性太低,走索引比走全扫效率更差,还有一个比较常见的就是对索引列进行了运算,导致无法走索引。其它还有很多原因会导致不能走索引,详细参考MOS文档:Diagnosing Why a Query is Not Using an Index (文档 ID 67522.1)。
以上就是解决CBO的SQL优化问题(图文详解)的详细内容,更多请关注php中文网其它相关文章!
学习教程快速掌握从入门到精通的SQL知识。
关键词:处理CBO的SQL优化问题(图文详细说明)